
I transformed a raw HR analytics CSV dataset into a fully organized relational database using PostgreSQL. The project involved thorough data cleaning, including the removal of duplicate rows and validation of data integrity, followed by structuring the dataset into multiple normalized tables to optimize storage and querying efficiency. I also prepared and transformed key tables and columns specifically for advanced data analysis in Python. This project highlights my ability to manage real-world data workflows, from initial ingestion and cleaning to database normalization, relational modeling, and final data export, showcasing strong skills in SQL, database design, and data preparation for analytical environments.
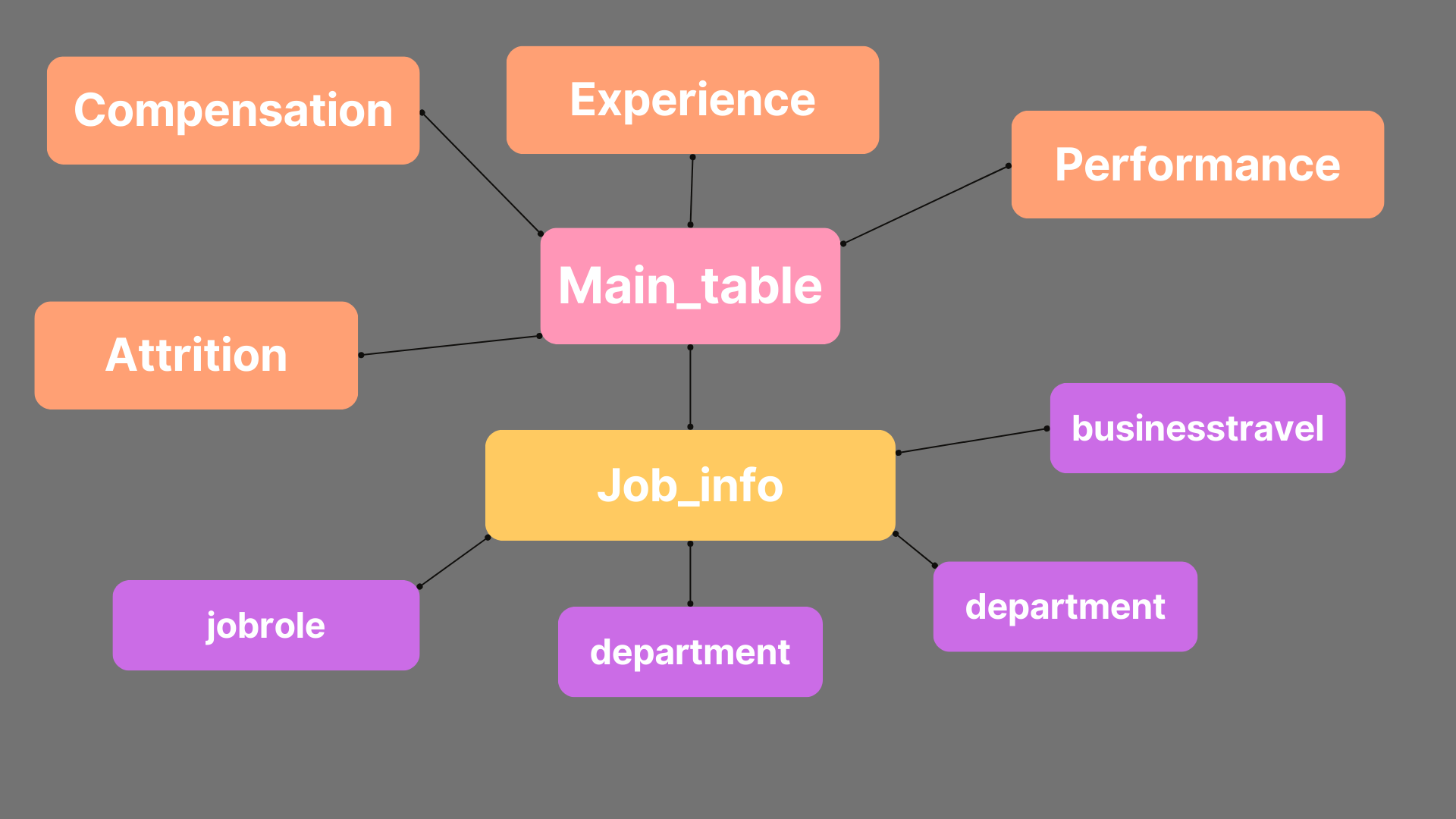
Orci maecenas
Nullam et orci eu lorem consequat tincidunt vivamus et sagittis magna sed nunc rhoncus condimentum sem. In efficitur ligula tate urna. Maecenas massa sed magna lacinia magna pellentesque lorem ipsum dolor. Nullam et orci eu lorem consequat tincidunt. Vivamus et sagittis tempus.
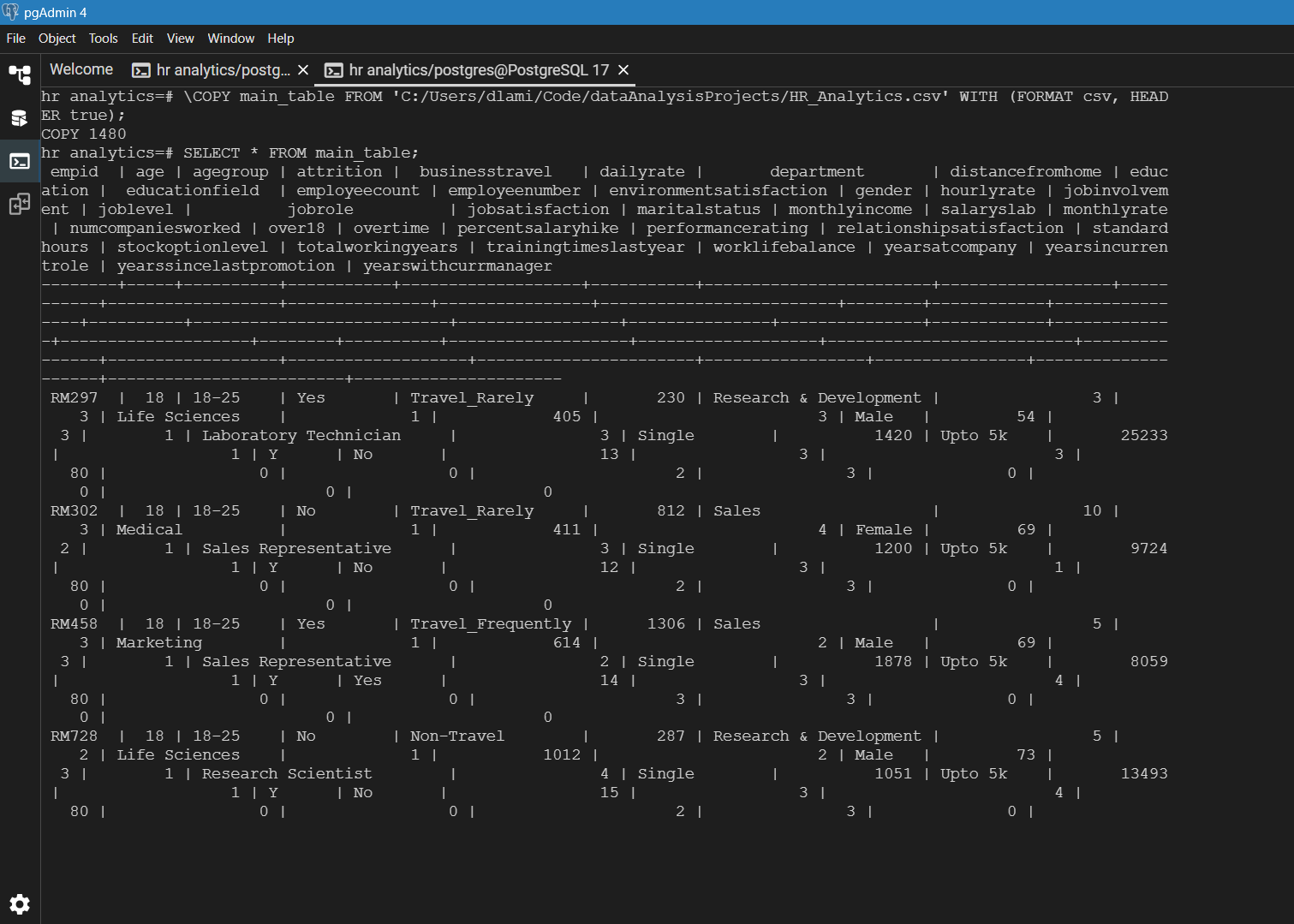
This image captures the process of uploading a CSV file into a PostgreSQL database using pgAdmin 4. The dataset, HR_Analytics.csv, is imported into main_table for organization and cleaning. The SQL command ensures structured data for deeper analysis. The table contains HR-related attributes like employee ID, job role, and attrition status. This step sets the foundation for workforce insights and analytics.

This image highlights a SQL script executed in PostgreSQL to clean and structure HR data. The process involves identifying and removing duplicate employee records based on empid using a Common Table Expression (CTE). After eliminating duplicates, the empid column is assigned as the primary key to ensure data integrity. This step enhances database organization for reliable workforce analytics.

This image showcases a SQL script executed in PostgreSQL to clean and structure HR data. The process involves transferring relevant employee records into a performance table using SQL commands. Attributes like job satisfaction and environment satisfaction are imported to ensure data organization. The primary key, empid, is set to maintain data integrity. This step lays the groundwork for workforce performance analysis.

This image illustrates the process of creating a compensation table in a PostgreSQL database using SQL commands. The dataset includes key salary metrics such as monthly income, daily rate, and stock option levels. The SQL script ensures accurate data migration from main_table for structured financial analysis. The output displays employee compensation details, laying the foundation for insightful workforce analytics.

This image illustrates the creation of an experience table in PostgreSQL using SQL commands. It captures key career attributes like total working years, job tenure, and training history. The SQL script ensures accurate data migration from main_table for structured workforce analysis. The data output displays employee records, setting the foundation for career progression insights.

This image showcases a SQL script executed in PostgreSQL to refine HR data by dropping multiple columns from main_table. The removed fields include job-related attributes, salary details, and satisfaction metrics, streamlining the dataset for further analysis. The query editor displays the command structure, while the data output reveals the remaining key attributes. This step ensures a more focused database for workforce insights.

This image highlights SQL commands executed in PostgreSQL to establish foreign key relationships across multiple tables. The empid column in main_table serves as the reference key for attrition, compensation, experience, jobinfo, and performance tables. The ON DELETE SET NULL clause ensures referential integrity by nullifying foreign key values when linked records are removed. This step strengthens database connections for effective workforce analytics.

This image illustrates SQL commands executed in PostgreSQL to create a Business Travel table and establish relationships with the job_info table. The script selects unique business travel categories, assigns corresponding IDs, and updates the job_info table with related travel details. The output displays employee records structured for comprehensive workforce analysis.

This image captures SQL commands executed in PostgreSQL to refine the job_info table. The script adds educationfield_id to link education field data, ensuring relational integrity. The process updates entries with corresponding values and removes redundant columns like jobrole, department, and businesstravel. The resulting dataset is more structured for workforce analysis.

This image highlights SQL commands executed in PostgreSQL to refine the job_info table. The script removes columns like businesstravel and educationfield, ensuring a more structured dataset. Foreign key relationships are established, linking jobrole_id, department_id, businesstravel_id, and educationfield_id to their respective tables. The ON DELETE SET NULL action maintains referential integrity, enhancing database organization for effective workforce analytics.

This image showcases SQL commands executed in PostgreSQL to create and populate an agegroup_count table. The script groups employees by age range and calculates the number of records per group. The output displays age categories and their corresponding employee counts, offering insights into workforce distribution. The dataset is structured for demographic analysis.
Massa libero
Nullam et orci eu lorem consequat tincidunt vivamus et sagittis libero. Mauris aliquet magna magna sed nunc rhoncus pharetra. Pellentesque condimentum sem. In efficitur ligula tate urna. Maecenas laoreet massa vel lacinia pellentesque lorem ipsum dolor. Nullam et orci eu lorem consequat tincidunt. Vivamus et sagittis libero. Mauris aliquet magna magna sed nunc rhoncus amet pharetra et feugiat tempus.